The potential for reducing the burden on an overstretched healthcare system means exploring Artificial Intelligence needs to feature on every progressive NHS Board’s agenda.
GlobalData’s recent study found that Artificial Intelligence (AI) is the emerging technology that will likely have the greatest impact on the pharmaceutical industry in 2021. Furthermore, US research firm Trinity Life Sciences observed that 90% of large pharmaceutical firms kicked-off AI projects in 2020.
Closer to home, Cambridge University announced a 5-year agreement with AstraZeneca and GSK to fund the Cambridge Centre for AI in Medicine. This will develop AI and Machine Learning (ML) technologies aiming to transform clinical trials, personalised medicine and biomedical discovery.
A multi-disciplinary approach of Medical, Statistical, Computer Science and Linguistics will transform Healthcare over the coming decade. However, AI, ML and Deep Learning get used interchangeably which adds to the confusion, so let’s try to break them down.
In the early 1950s, there were various names for the field of “thinking machines”: cybernetics, automata theory, complex information processing (“Machines Who Think” by Pamela McCorduck, 2004). In 1956 scientists gathered at a Computer Science conference at Dartmouth College to discuss Natural Language Processing, Neural Networks, Robotics and Computational Theory, and the umbrella term Artificial Intelligence started gaining popularity.
Alexa, Siri, Self-driving cars and even fictional characters like the Terminator can all trace their roots back to these field’s convergence.
AI is generally divided into 2 categories (Weak and Strong AI), spread across 3 stages of development (ANI, AGI, ASI).

Weak or Narrow AI performs a specific task, sometimes even better than humans, but does not replicate human “general” intelligence. Think back to the famous Deep Blue that beat chess master Garry Kasparov in 1997, but would have been flummoxed if you asked it to order a pizza that today’s AI personal assistants can do in a digital heartbeat.
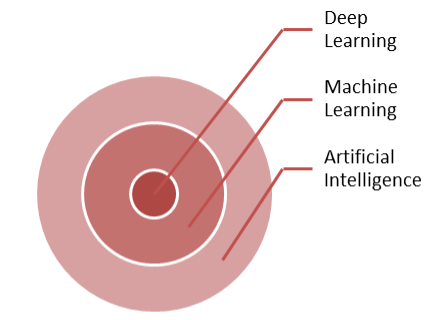
Machine Learning is a subset of the broader field of AI, and Deep Learning is a subset of Machine Learning. It’s a way of teaching a computer without programming it specifically for that task, as we will see below.
At its most basic, any software has 3 parts – Input, processing based on Rules, and Output. You code the Rules as an algorithm, provide the Input (data), and get an Output (answers or action). Traditional software is pre-programmed with an algorithm that knows how to process the Input and generate the Output. In other words, feed in Rules and Data, get Answers.
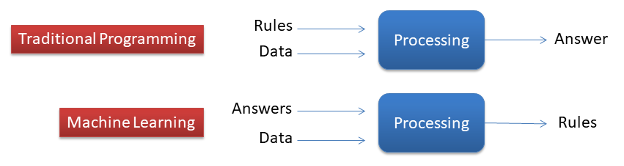
Instead of defining and pre-programming all the rules as you do in traditional programming, Machine Learning means you provide lots of labelled Answers and the machine infers the Rules. As you feed it more Answers, it will improve its understanding of the Rules. This means it can increase the chances of guessing the right Answer when given real, unlabeled Data.
Take the example of a camera in your car that should warn you as you approach a STOP sign. In traditional programming, you would write reams of code to recognize the octagon shape, take into account variation such as size, shade of red, height from the road, dirt or leaves obscuring part of the sign, differences across countries etc. Conversely, in Machine Learning you would feed it lots of images of labelled STOP signs and let it infer the rules of what separates a STOP sign from other road signs.
By giving the machine lots of labelled answers, you have allowed it to figure out the rules of what a STOP sign is, so that next time it will recognize it when it sees one.
There’s 2 broad ways you can train a machine: 1) using structured (as in the example above) or 2) unstructured data.
Structured data is most often associated with Supervised Learning, where you tell the machine what Features to learn (e.g. shape, size and colour of the road sign). For more complex situations (e.g. detecting credit card fraud), the variations in Features are too many to predefine so you resort to Unsupervised Learning. This is where the program can even start to pick up patterns that humans might have missed.
Neural Networks are one of the advanced ways of implementing Machine Learning. They mimic the way the neurons in our brain work, sharing data by passing tiny signals to each other.
They are made up of Nodes spread across layers – an input layer, one or more hidden layers, and an output layer. Each node is connected to the nodes in the next layer and has both a weight and a threshold. If any individual node’s output is above the specified threshold value, that node is activated and sends data to the next layer. Otherwise, the node isn’t activated and no data is passed to the next layer.
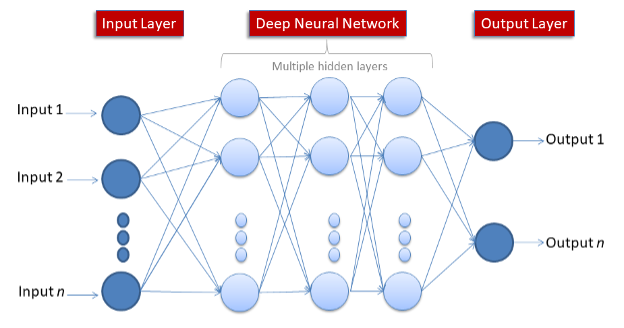
The number of hidden layers increases the network’s complexity and power. The term Deep Learning is used to describe Neural Networks with 3 or more layers.
Looking beyond the hype, there are numerous practical applications of these concepts. According to an Accenture analysis, key clinical health AI applications can potentially create $150 billion in annual savings just for the United States healthcare economy by 2026. The potential of bringing healthcare to the most deprived nations is even more enticing.
I was recently asked “isn’t Machine Learning just glorified Statistics?”
Machine Learning also uses some of the same methods as Statistics including Regression, but the two serve different purposes.
Let’s take the example of a patient survey, such as the FFT (Friends and Family Test) used by the NHS that is based on the widely-used NPS (Net Promoter Score). Regression will result in a numerical (continuous) outcome (e.g. the strength of the relationship between ethnicity and overall satisfaction); while Machine Learning can be used for classification (discrete) of free-text comments (e.g. classifying comments into themes such as compassion, friendliness, communication).
The former should guide our thinking on how input variables (age, waiting time, treatment type) impact the outcome variable (patient experience), while the latter will show the themes emerging from the comments left by patients. Of course it’s not enough to know that 15% of the comments were about friendliness – they need to be further classified as positive or negative to fully understand what the patients felt.
It’s by combining these approaches that we will truly begin to understand – and improve – the patient experience.
From exciting Robot-assisted surgery and Automated Image Diagnosis, to more mundane but cost-saving applications like chatbots to enhance the patient experience, the potential for reducing the burden on an overstretched healthcare system means exploring Artificial Intelligence needs to feature on every progressive NHS Board’s agenda.

