By Michalis Michael
Before we start sharing real data and case studies from social listening, we thought it prudent to explain how this is properly done for market research purposes. The most important notion to be understood and accepted is that unlike the way DIY social media monitoring tools work, in order to achieve the required data accuracies that are of paramount importance for market research purposes, a 3-4 week human-led set-up phase is needed (see Fig.1). Once the set-up of a product category or any other subject in a specific language is done, from then on it is possible to take a real-time DIY approach like with any other social media monitoring tool.
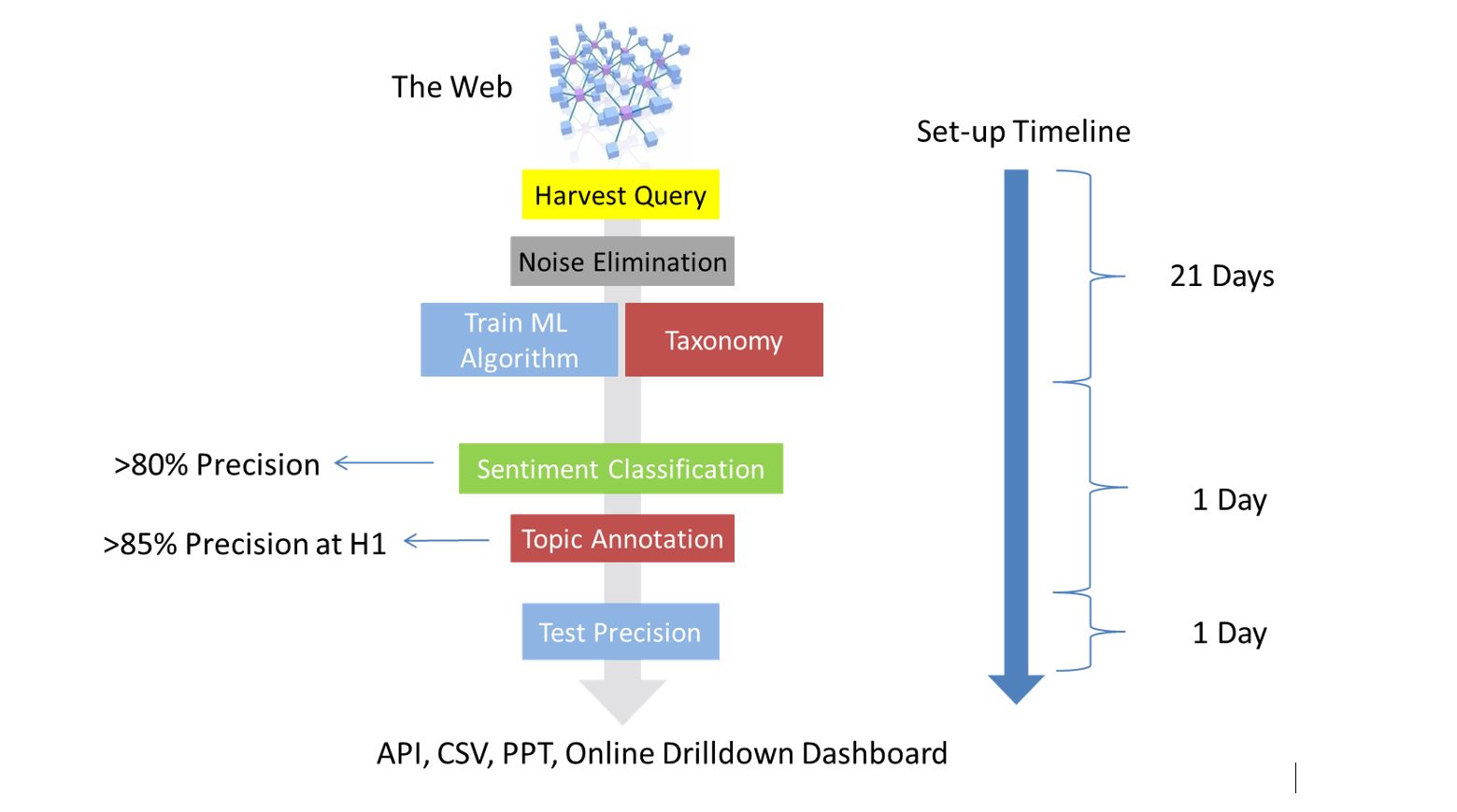
Figure1: Social Media Listening & Analytics Process for MR (Source: DigitalMR Presentation at LT-Accelerate Conference 2015)
In the first article of this series, we mentioned that it is important for insights experts to be able to connect the dots between listening, asking questions, and tracking behaviour. In order to do that, an insights expert needs to trust that the thousands of posts analysed are actually about the brands and product category of interest. This brings us to the first of 3 issues to pay attention to when using social listening for market research purposes.
- Noise Elimination
The set of keywords that is used to collect posts from social media and other public websites is called a “harvest query”. This harvest query can be as simple as one word or as complex as multiple pages of Boolean logic. The problem with harvesting only the relevant posts is that we need to also know all of the irrelevant synonyms and homonyms of our keywords; which we never do. Thus, an iterative process is required, involving humans who can improve the harvest query as they find new irrelevant words that they did not think of during the previous iteration. The most common example we use to make this clear is this: when we want to harvest posts about “Apple computers” we know from the beginning that there will be posts about apple the fruit, so we create a harvest query that excludes posts about the fruit; but what about (the actress) Gwyneth Paltrow’s daughter named Apple that everybody talks about on Twitter? I’m sure you see my point…
- Sentiment Accuracy
There are quite a few ways to annotate posts with sentiment, ranging from manual to using linguistic or statistical methods of NLP (Natural Language Processing). There are pros and cons for each method especially when we are looking at a data set with 10,000 posts or fewer that will be used for a one-off report. However, for any continuous reporting or even a one-off report with over 20,000 posts, using humans as opposed to machines is both expensive and slow. In the previous article of this series we talked about the proper metrics for accuracy: Precision & Recall. Most social media monitoring tools can barely achieve a sentiment precision of 60%; as a matter of fact in all cases when we were asked to check, their accuracy ranged between 44%-53%. Anything over 70% sentiment precision could be acceptable at the beginning of a tracking project for market research, but then it should climb over 80% within a short period of time.
- Semantic Accuracy
When we say semantic analysis we mean analysing the topics of online conversation around the product category of interest. Similarly to sentiment accuracy, precision & recall are the appropriate metrics to measure semantic accuracy. If a hierarchical taxonomy (a dictionary with multiple layers/hierarchies that describes a product category with the words people use in their social media posts) is used to report on topics for market research purposes, over 85% semantic precision for hierarchy 1 topics is achievable. You will have noticed that even though we mention “recall” as one of the accuracy measures, in this big data analytics space we have not used it to describe what is appropriate for market research purposes. Recall for semantic analysis is about how many of the posts that actually exist in a data set on a certain topic, were identified as such. In the world of big data where we deal with millions of posts, in order to be cost efficient, it is in our interest to only look at keywords that are mentioned multiple times. If a keyword is mentioned only a couple of times in a data set of millions we will be entering in “diminishing returns territory” if we attempt to annotate posts with it. It is however possible to maximise recall and it should be the end-client’s decision if they want to spend their money and time this way.
Let me know if you have questions; in the meantime, stay tuned for the next article which will be about some real data from social listening.
By Michalis A. Michael, DigitalMR, Connect with Michalis via @DigitalMR, his personal @DigitalMR_CEO or via email mmichael@digital-mr.com

